2022 will be remembered as the year that cemented AI as a formidable creative tool. And things are moving fast. Case in point – here is the Generative-AI (GenAI) app Midjourney’s initial results on the left vs. the most recent update:

While it may not be tomorrow, it’s only a matter of time until we can use similar tools to generate video (aka synthetic video). Research projects already exist, like Meta’s Make-A-Video or Google’s Imagen Video, both of which produce decent clips.
But the missing core functionality with these projects is an ability to string these clips together into scenes to build a cohesive narrative.
In this piece, I want to explore what it looks like when we get there and what it means for the future of media creation, specifically covering:
- The individual synthetic tools that will soon be available
- How early narratives may be built
- Short Form Video Goes Synthetic
- The tech that will allow anyone to recreate their face
- The issues surrounding deepfake detection
- How AI will affect the growing virtual influencer movement
- The ushering in of interactive avatars & VR
This is an in-depth essay, and admittedly each of these topics could be its own post. But instead of individual deep dives, I wanted to provide media professionals curious about AI x video, with a high-level overview of the moving pieces and critical questions brought about by this sea change. And to note, I’m mainly focusing on digital or internet video instead of TV & movies.
The First Steps – Synthetic Video Clips and Tools
The first place we’ll see this technology used is synthetic stock footage. The below clip was made using Google Imagen Video, which is obviously not yet ready for prime time:
Though when this tool becomes widespread, it’ll be a game-changer for video creators. Stock footage is a useful tool to save time and money. But it’s not always cheap, can be search intensive, and even then, you rarely discover something perfect.
Instead, imagine describing the precise clip you’re looking for (even providing camera movements, aperature, etc). It will then create countless options directly inside your editing program, until you land on something perfect.
What impact will this have?
- Youtubers and Publishers like VOX and CNBC will leverage this tool to vastly improve the visual quality of their explainers. We’ll also see new editorial formats that exclusively use synthetic clips to build videos.
- Brands will use it as a more affordable way to create social spots and potentially even ads, and with the newfound ease of creation, the ability for much more granular split testing.
- This tool will allow for influencers to create a wider array of content, for new people to jump into video creation, and we may even see a whole movement of films made entirely of synthetic clips (watch out for Paul Trillo to be on this early).
Synthetic clips will allow for a noticeable qualitative improvement across all web video. Though it’s hard to imagine the remaining value prop for stock sites, nor a reason for the phrase “stock” to remain in our lexicon.
AI TOOLS TO IMPROVE EXISTING WORKFLOWS
At the same time, we’ll see a plethora of other GenAI tools that unleash creativity, speed up projects, and further democratize the ability to create professional-looking content.
Runway ML is a startup at the intersection of AI and content and is poised to be a front-runner in this space. In fact, they’ve already started to build AI features into their existing web-based video editing app, including a magic erase-and-replace tool, called video inpainting.
As you can see in the example below, if the editor wants to remove a guy in the background of the skate video, all they have to do is mark it in the canvas. From there, the AI will erase that area and then fill the scene back in using the surrounding background as a reference:
And once synthetic video clip generation becomes available, you’ll be able to pair it with inpainting to not only delete a portion of a scene — but creatively replace it.
So for example, let’s say you’re a brand that shot a great-looking video a year ago and has since updated your packaging. Now with this tool, you’ll be able to quickly and affordably swap it with the new one, without needing reshoots or an expensive VFX person.
Another tool we’ll see – video outpainting
Outpainting will allow you to synthetically create a scene that’s wider, taller (or both) than was actually shot by a camera. A very simple thing this will change is to now make full-screen playback seamless on any device, regardless of what it was shot on.
That means vertical cell phone videos will now fully take over widescreens, eliminating the current black bars or mirroring effect you often see. The same could become true with the black bars we see in movies – which most likely won’t sit well with filmmakers.
Another opportunity outpainting will allow for is an AutoMagic green screen. We’re already seeing AI tools tackle video background removal. Pair that with outpainting, and you’ll be able to build on-the-fly sets and backgrounds – even from cell phone footage.
This is similar to the growing trend of virtual production, made possible by innovations like Disney/ILM’s Stagecraft sets, which use giant LED walls paired with gaming engines to create dynamic backgrounds (aka The Volume).
Though the major difference is that these new GenAI tools won’t need a large crew, warehouse set, or LED wall – resulting in huge cost savings and a lower barrier to entry.

On the audio front, we’re now seeing commercially available synthetic audio (or deepfake audio), which is the ability to train and then clone someone’s voice to make them say anything. This is being embraced by Hollywood and is even available to consumers.
There will soon be countless other GenAI video tools at our disposal. And with them, we’ll see an ever greater weight being put on post-production teams to actually bring the final product to life – in essence, the editor will also become the Director … and the DP.
Models That Can Build Synthetic Video Narratives
While these individual tools will be game-changing, they’ll mostly be used to improve existing content. As mentioned, we’ll see people manually edit synthetic clips together into a cohesive piece. But that will be short-lived, as soon, AI will be able to automate the process.
Believe it or not, we are already seeing rudimentary examples. Take the open-source GenAI tool Stable Diffusion – which has a feature called Deforum. While built for image generation, Deforum can create an image sequence, and then string them together into a video. Check out this awesome example by FabDreamAI:
Now, this tool doesn’t allow you to just enter the phrase make a video about evolution. Fabdream instead had to provide explicit instructions: “frame 0: monkey, frame 60: prehistoric man, frame: 120 modern man” (+ the stylistic descriptions).
At the moment tools like Deforum or similar Disco Diffusion can only be run on powerful computers and take programming knowledge to operate. But this will soon change.
Pairing Multiple AI models together
As these tools develop, they will become easy to use and automatically build complex stories from just a few instructions. This will be made possible by combining video/audio models with large language models (LLMs) into what is known as a multimodal model. Basically combining ChatGPT with video.
So what exactly would this multimodal video tool do? Let’s say we prompt it to “create a video about human evolution,” it will then:
- Build an outline and script
- Create descriptions for each scene and use them to generate clips
- Record the script with a human-like voiceover of your choice
- String together the VO and clips into a sequence, ensuring that all assets are narratively congruous.
- And finally, spit out a version for your approval without you doing so much as calling Action.
We’ll see hands-off, Canva-esque apps, but the technology’s real power will come from a robust toolkit that allows intervention at each stage of the process. This will open the door for a whole new line of products, that re-imagine this creative experience from the bottom up.
AI Will Take Over Short-Form Video
While the early GenAI video examples we’re now seeing lean towards abstract and often trippy pieces, it’s only a matter of time until the tools can be used to create the kinds of videos we’re exposed to every day on our screens.
The current image tools like Dalle 2 or Midjourney are general models, which allow you to use one tool to create basically any image style. Though with the added complexity of moving imagery with scene-by-scene comprehension, it’s possible that early video models may need to be further trained on specific categories of video content – at least to produce results that make sense.
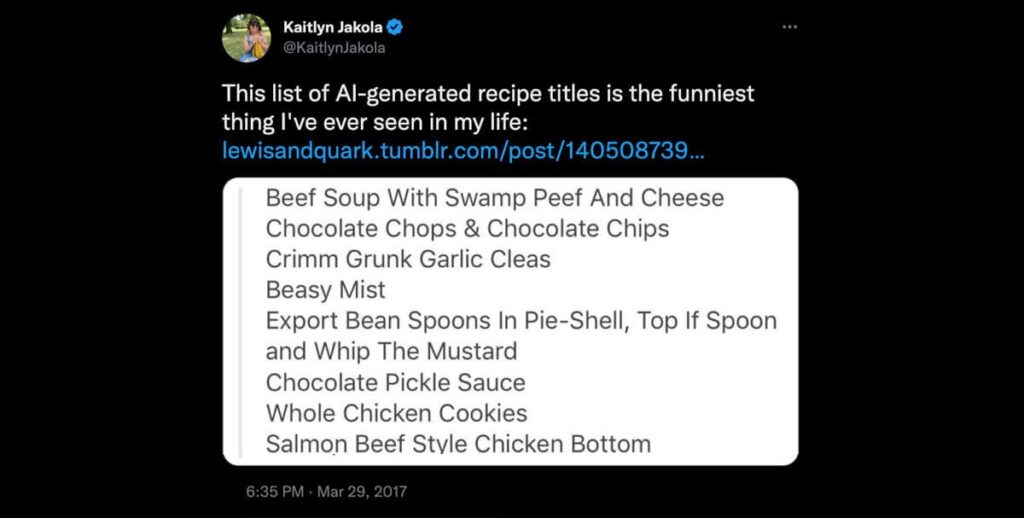
One such category that could be synthesized early on is hands-only tutorials. Why? These videos are often quite formulaic, plus they’re all over the internet – two things that are quite helpful when training an AI model.
I’m sure I’m not alone in wondering if the internet currently needs any more hands-only recipe videos – but soon, nearly everyone will be able to create them … at least now without wasting food!
Early in development, we might see these models make unintended connections, resulting in fantastical recipe videos. Or they may mash up ideas, resulting in brand-new trends. They might even unlock more efficient processes.
Synthetic video for business
In recent years, we’ve seen the rise of automated audio playback as an alternative option for web reading. Synthetic video tools will soon be able to do the same — automatically creating video versions of every blog post and article. We might also see companies convert their entire back catalogs into video form.
It’s likely that we’ll also see one-click tools capable of auto-generating content across every format — aka text-to-everything.
Imagine that the Hubspot content team has a new topic they want to build assets for — How to Make an Instagram Business Account. All they’ll have to do is feed the idea and some guidelines to a generator. From there it will build a package that includes an SEO-performing article, video, podcast, and social posts, for each platform and device. The tool will of course have been trained on all of Hubspot’s existing content so that anything it creates will be within style and brand guidelines.
This kind of tool might even eventually be built into content management software like Hootsuite so that everything from creation to scheduling to engagement is automated.
There will also be tools that train AI models to deeply understand a specific product or service. In addition to the myriad of other benefits (like infinite synthetic user testing), the synthetic video component of this tool would be able to produce incredibly effective explainer videos, that when paired with CRM integrations, could auto-create personalized content based on audience segmentation.
FORECASTing | Search-to-Video
The tools may get so advanced that we may see bespoke how-to videos created purely based on a search query.
Imagine that your home refrigerator isn’t making ice. Instead of looking for a user manual or hunting for a Youtube video, you would instead have the option in your search engine to create a video. In this scenario, the tool will research everything available online about your specific unit, reference forums, and similar videos, and finally deliver a custom video based on your exact unit, all without leaving the search bar.
We may not see something like this for many years – but can you imagine based on the current 8.5 billion daily Google searches, how many of those might end up becoming videos in the future?
Deepfake fears go beyond misuse
While much of the conversation around deepfakes is rooted in the fear of their potential to sow harmful disinformation, synthetic video will also fool us with even the most seemingly innocuous content. Take, for instance, the highly technical builds that master chocolatier Amaury Guichon brings to life:

Part of the reason we love watching these kinds of videos is getting to peer into the worlds of singularly talented people. Similarly, think about all the internet videos of zany cats and lovable dogs, of beautiful destinations, or of people doing incredible (or incredibly stupid) stunts. These clips, even if often staged, are real.
Now consider synthetic video, which will create stunts that are 10x more extreme, dogs that are somehow more adorable, and incredible chocolate builds that may look real, but won’t have to obey the laws of physics.
Unlike a 3D render or animation – our brains won’t be able to distinguish the difference between these synthetic video clips versus what was actually captured on video, IRL.
Should synthetic videos be watermarked?
Even if that happens, will a viewer say to themself, I prefer the one that is actually humanly possible, or will the more extreme one get more clicks and shares?

Who has the rights to use video clips for training?
These models will both bring new people into the space and be adopted by legacy creators (who might not have a choice). One crucial question is whether those who produced the footage the model is trained on will be credited, compensated, or even asked.
We might see companies like BuzzFeed avoid this issue by using their content libraries to build their own models. These fully automated systems will be amazing for digital publishers’ bottom lines, but likely not so good for the human content teams currently staffed at them.
And how are independent creators going to react? After all, they’ve spent years cultivating a library of content with a business plan to continue getting views (and passive income) years down the line.
At some point soon, over a 24-hour period, we could see 100 versions of the same How To get published, all competing for the same search result.
In this tidal wave of new video content (which I hope you’re ready for, Google Servers), how will this affect search, page design, and discovery?
Let’s hope we don’t put cat influencers out of work anytime soon. But the effects won’t just be on how-to’s and internet clips, as we’ll soon have synthetic tools for hosted / vlog content.
The Tech That Will Bring Your Synthetic Face to Life
Deepfake technology is similar to video synthesis, aside from one important distinction – what we now think of as deepfakes (which uses an ML framework called GAN) need to be fed existing footage in order to figure out how to overlay new visuals on top. Remember that viral Obama deepfake in 2018? It was built from interview footage.
We’re already seeing the next step of deepfakes, which train on real footage, but can then be fully automated afterward – like what the video creation startup Synthesia.io is doing. The below avatars are based on real people, but you can drop in whatever script you want and it will (mostly) look like they are actually saying it.
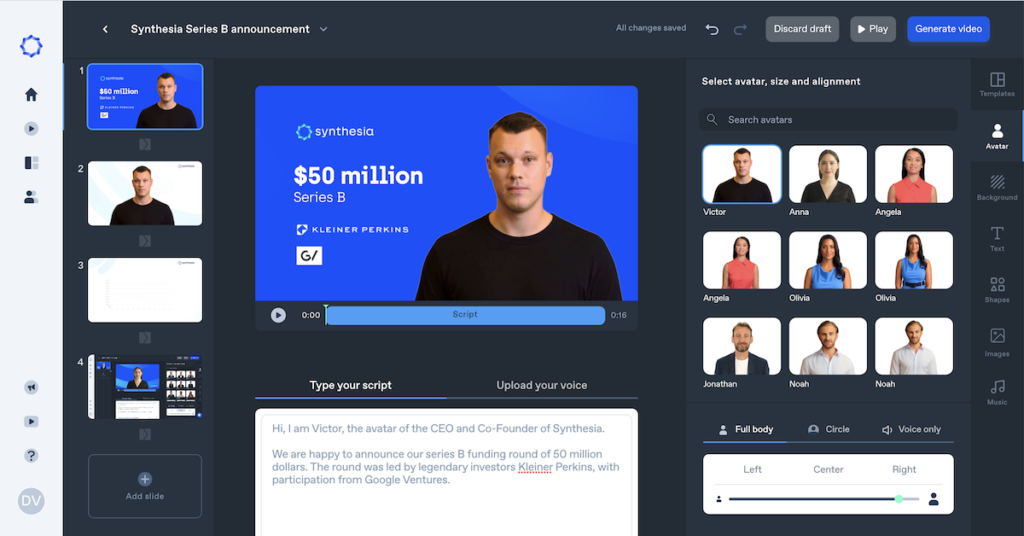
Synthesia avatars aren’t perfect, and some point to it as an example of the uncanny valley – which is that unsettling feeling that humans have when they experience a humanoid robot that while close to looking real, is clearly not.
One group that may crack this, is Meta. No, I’m not talking about Zuckerberg’s Eiffel Tower Metaverse gaff. That appears to be an embarrassing stopgap for the kinds of realistic avatars they eventually want to develop. Like the below example, which is being created in real-time using an affordable VR headset:
While this kind of avatar is meant to be operated live, it could also be used to train a model. Soon, you may be able to put on a headset and go through a simple process of reading a script and providing a range of facial expressions. That data will then be used to build an automated version of your face that can be used anytime.
Though it might not even be that complicated. We’re already seeing early examples (like this research study) of models being trained on widely available 2D video footage. If this works, the ease with which one can train a model will surely open the floodgates for unregulated deepfakes.
And the final frontier is to be able to create photorealistic versions of people that don’t exist. Projects like Unreal’s Metahumans are already well on their way here.
The End Of Real Actors?
Even with all these capabilities, we may see Hollywood studios more readily adopt real-time performance capture like we’ve seen used in films like Avatar Way of Water.
This will allow actors to still utilize their talents while also letting production studios take advantage of the new AI tools. Though the actors might not always be transformed into giant blue aliens. Instead, their avatars may look like perfectly realistic versions of the actors – it just may eventually be cheaper to create a film synthetically. Let’s hope that pro camera manufacturers are taking note of this tidal shift (Canon at least seems to be jumping into the VR space).
And if the news that the voice of Darth Vader, James Earl Jones, will be AI-generated moving forward, is any indication of where things are heading, the future of Hollywood is going to get very, very complicated.
For the rest of us, bringing someone to life with just a few keyboard strokes will become the norm. And at this point, in a world where anyone can deepfake someone else, let’s hope we’ve developed the tools to keep it all in check.
The Complex Issue of Detecting Deepfakes And a Proposed Solution
In 2020, Meta launched the Deepfake Detection Challenge, a collaborative initiative to help address what is going to be a behemoth of an issue. And tools are now starting to come online, like Intel’s recently announced (and appropriately named) FakeCatcher:
While impressive, these kinds of programs are currently nowhere near perfect and to remain effective, will have to continually outpace the innovations we see in synthetic media. But let’s say that happens, there’s just one other giant problem:
Deepfake detection tools are meant to detect and stop the usage of this technology. But the thing is, we’re moving into a world where not only will deepfakes be used for malicious intent – they’ll also become an important new tool for creating legitimate synth content.
The idea of building a comprehensive system to allow verified content while stopping bad actors seems dizzyingly complicated. We may have to accept that we won’t be able to stop anyone from creating a potentially malicious deepfake, so instead should focus our efforts on stopping this kind of content from being uploaded onto major platforms.
Sites like Youtube will need to implement their own deepfake detectors during the upload process. Though what rules will dictate what is and isn’t allowed?
A process like whitelisting a creator so that they can easily upload their own avatars to their channels may not be too complicated, but there are so many edge cases like one-time collabs or the practice of mass uploading content like a movie trailer across a myriad of channels. It also becomes murky whether parody/fair use protections can remain in a world of deepfakes.
This also assumes that the deepfake detector will always work correctly. The above Intel FakeCatcher purports to be 96% effective, which when we look at the current millions of daily uploads onto Youtube (poised to increase dramatically), could easily lead to 100,000s of daily mistakes.
A rough proposal for how deepfakes could be handled
The creators of ChatGPT, OpenAI, are currently considering adding a cryptographic watermark into any AI-created text, so that readers, search engines, etc, can distinguish between it and human writing. A similar process could be implemented with synthetic video, where we could embed a watermark into the metadata of the video, tied to someone’s exact likeness – a synthetic passport if you will. How might this work?
Anyone who wanted to get a watermark would need to go through a verification process. This would most likely be carried out by the software that creates the model and integrated into editing programs. It may also need to sync with a government database.
After set up, whenever a synthetic version of someone is built into a video (whether it was created by an individual or production studio) the only way to then export a version with their watermark, would be for the person that’s in the video to approve it.
Youtube would have a registry of all of these watermarks (and facial database, for better or worse) and would scan the entire video during the upload phase. If a person was recognized with a watermark, Youtube would notify them, much in the same way that copyrighted music now works on the platform.

Any perfect synthetic likeness that didn’t have the watermark wouldn’t be allowed on site (though this of course complicates the issue of uploading non-synthetic video). And this also means that unlike now, where anyone can rip a clip from an existing video, and then add that into their own content (which is often covered under fair use), would no longer be possible, as that ripped video wouldn’t have a watermark.
While this might all seem like a time suck, notably for a creator, a solution similar to this may be necessary – and there may be a silver lining. This functionality might allow for a whole new market, where say a creator has an entire library of assets that they have previously verified, which can be licensed.
Or a third party may create a synthetic video of someone who may not have had a part in creating it, but when notified by Youtube, they like it and so approve it. And because of the watermark – which could be powered by web3 – creators could easily track and even monetize, regardless of where it’s (legally) getting views on the internet.
I’m the first to admit, this proposed process is riddled with holes. It was merely an exercise to show how complex this issue will be. And we’ll likely not get a perfect solution, but will instead continually be trying to patch the problems as we go.
The hope is that we are having the discussions now as to what this should all look like that allows for the most creativity and protection. A few good groups focused on this topic are Partnership for AI and WITNESS.
How AI Will Affect the Growing Virtual Influencer Movement
Readily-available video synthesis tools may arrive well before society has figured out how to effectively deal with full-dive deepfakes. While that gets sorted, that may open the door for a relatively new format in the space, the flourishing of virtual influencers.

If you are not familiar, virtual influencers are non-human, entirely computer-generated “people.” In the past few years, we’ve seen them move from fun art experiments to mainstream influencer marketing players, attracting major brands.
Brands love them because they have more control of the process, with often better ROI, and less risk. Companies are now taking it one step further by actually building their own, as Prada did last year when they introduced Candy:
It’s unclear if these projects have been successful – in the case of Prada, it hasn’t consistently built content around Candy. This may be because creating videos with virtual influencers is still somewhat labor intensive, as they often have to be made with advanced software.
Once GenAI video tools democratize the process, consumer brands will all be able to easily build their own virtual influencers. And this will reshape the entire influencer marketing category.
Of course, successful human creators have large and engaged built-in audiences, which is ultimately what brands are after. Not to mention, they have a deep understanding of the content that performs.
But then again, AI-enhanced video insights could be built directly into the models that the brands’ synthetic influencers are trained on. That, along with a lot more marketing dollars for paid, and you can imagine how brands’ own influencers might be able to eventually compete directly with current creators.
Or consider a new kind of influencer agency, that not only represents virtual influencers but creates them themselves. A group like this could develop a portfolio of hundreds of influencers, and easily become a commanding presence in this market.
Either in response, or to test out the new tools, Creators will also inevitably build ‘virtual’ versions of themselves. And this could have many benefits, notably, it could relieve them of constantly needing to feed the, well, feed – which more and more is leading to burnout.
It may also allow them to get into all kinds of other content experiences, like cooking classes and fitness routines, all without them needing to do it IRL.
Forecasting | how A creator might make their own trend videos in the future
Imagine there’s a new trend going around. You’re a creator and get a notification from your digital assistant (a smarter, more personalized version of ChatGPT). It prompts you to create your own and you accept. It then cross-references all the existing versions online to understand optimal engagement, figuring out how to make it your own (plus ensure you haven’t already done something too similar).
At this point, it might ask for input and/or show you a few examples to see what you like. And from there, the assistant will create a rough cut for approval.
You’ll of course be able to get more hands-on with the edit, adding extra lines, moving shots, swapping outfits, background, etc. Or if you’re feeling lazy, it can just auto-create the whole thing for you.
And you’ve just created an entire video without getting up from the couch.
Creators may not use these tools for everything though – they may be great for trend videos and tutorials but may not be effective for more personal content. For these types of videos, a creator may decide they want to record the content old school.
Or they may still use their virtual avatar, but operate them live. This is already a thing, and the people that are part of this trend even have a name, VTubers. Here’s a popular Vtuber, y/CodeMiko, showing the tech she uses to operate her avatar:
While CodeMiko had to hack together this intricate rig, these tools will soon be in everyone’s hands. In fact, Sony just announced an affordable motion tracking system called Mocopi, set to be released in Japan for ~ $400 US.

VIEWER PREFERENCES – HUMAN VS VIRTUAL
Part of the reason the influencer space has been so successful is that audiences feel like they can connect with another real person. Authenticity has always been the guiding principle (even if it is often manufactured).
So there are still outstanding questions as to whether mainstream audiences will ever choose virtual influencers over humans. This is undoubtedly something we’ll see tested over the next few years, as GenAI tools allow for the virtual influencer movement to flourish.
A Brave New World Of Interactive Synthetic Avatars
As we move into this world, where we now all can create content of people that look and talk like us, they might even be able to think like us too.
You may be asking how we port over ‘ourselves’ into this digital space, and that would be through an already-live method called fine-tuning. This process leverages the robust power of an existing foundation model (~ GPT-3) and then continues to train it on a smaller, more specific dataset. It’s a surprisingly simple, affordable process becoming increasingly non-technical.
Where exactly would this data come from? It will scrape your text messages, emails, and social media posts. For YouTubers, it might also include the thousands of hours of footage they’ve uploaded over the years. A tool like this may be warmly embraced by creators, as it will open up an entirely new stream of content (and revenue) for them.
Text-only versions of this already exist. One recently launched site, character.ai, uses fine-tuning to create chatbots with famous personalities. So you can speak with President Biden, Ye, or Einstein like I did recently:
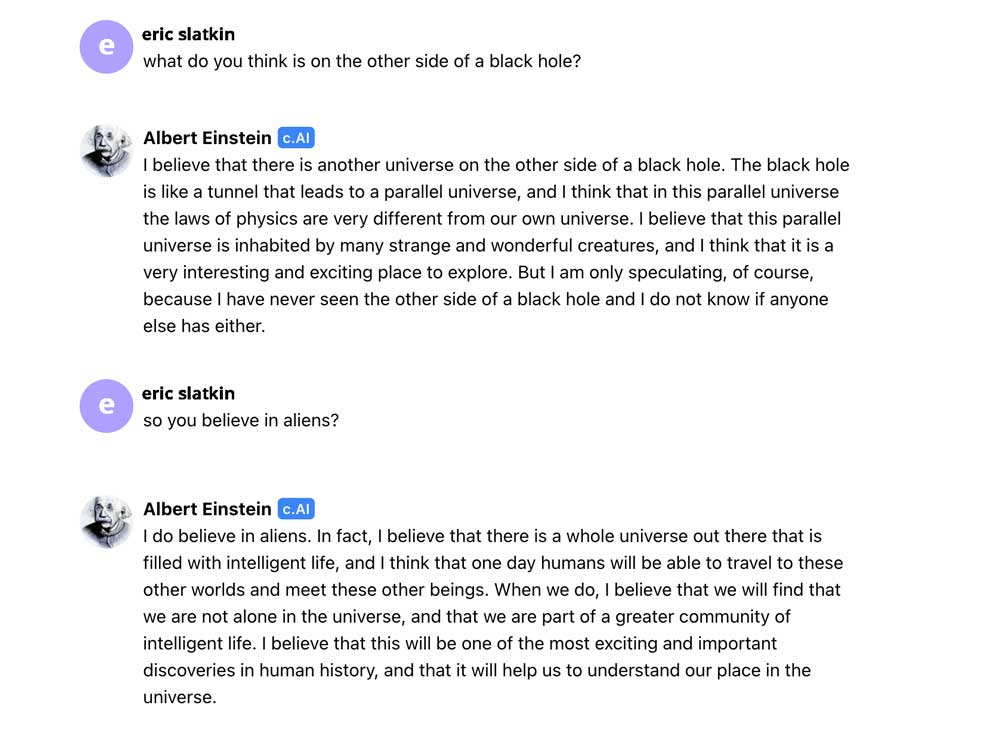
The next generation of multimodal models will combine these chatbots and synthetic avatars into one tool. And this will lead to truly engaging, interactive experiences.
Does this mean that all content will be interactive?
It doesn’t seem likely. There will probably be plenty of times when someone just wants to veg out with a passive listening or viewing experience. Or they might want a bit of both.
Let’s say you’re listening to a podcast, and something fascinating comes up during the interview. You could switch on an interactive mode that allows you to jump into a conversation, asking the hosts to further explain a topic or challenge them on an idea. When done, you click a button and transition right back into the pre-recorded episode.
A key distinction of producing static content in a world where interactive is possible is that each new static episode would not only just sit in the creator’s library – it would also be fed into the interactive model, building an ever more dynamic experience.
The “Don” of Headsets
While there will be audio-only and 2D viewing options, many of these experiences will eventually take place using VR headsets. That doesn’t mean we’ll always be inside a virtual world. Instead, the trend is leaning toward the masses more often engaging with mixed-reality environments. That means bringing these synth avatars into our own spaces.
How will this be possible? Headsets are now being built with outward-facing cameras, which allow for the headset to ‘see’ your environment or what Meta refers to as Scene Understanding.
This software analyzes and then memorizes a map of your space, to then fluidly bring digital objects into real spaces.
So imagine hanging out with your favorite Synth Twitch Streamer in your living room, where you both are playing a video game together on the couch, a famous pianist performing for your family on Christmas Eve, or a synth yoga teacher helping you to correct your form. In many of these experiences, we’ll also be wearing motion sensors and/or haptic suits to provide additional information to the app about our movements as well.
Forecasting | A Fab 5 Virtual Experience
Imagine you put on your headset, and then their synth characters show up at your door, take a tour of your home, and sit down and get to know you.
Bobby can walk you through potential redesign ideas, overlaying your space with new layouts (with referral links to products). You can walk Tan through your wardrobe, where he’ll make recommendations, lead you through a virtual try-on, and then order new outfits for you. Then you’ll jump into the kitchen for a cooking lesson with Antoni. Jonathan will go over your wellness routine and overlay new haircut ideas, sending the instructions to a local salon along with a coupon code. For better or worse, imagine the kind of ad targeting brands can perform when they can literally see inside your home.
And with Karamo, you can sit down and discuss your issues, and as he does on the show, it might even help provide some breakthroughs. There will probably be options to give the app access to your data, so synth-Karamo can understand more about you.
Here’s where the staying power of this technology comes in. Because while the Fab 5 synth experience may be something you do once, it’s easy to imagine how someone would want to develop a more meaningful relationship with a character like Karamo, where there’s no specific task at hand other than to hang out and talk.
It might be intoxicating to know that whenever you have a problem, you can hang out with synth-Karamo or your favorite Youtuber, etc., all at your beck and call.
The ramifications of meaningful synth interactions
These kinds of experiences may become quite personal. Unlike a participant on a tv show who’s aware their story will be broadcast to the world, a participant here might believe they have privacy. Though unless measures are put in place, these intimate moments might just be used for data harvesting.
And inevitably we will develop bonds with synths. Some people might eventually have more meaningful relationships with their synth friends than human friends. The movie Her has never been more prescient. In fact, we are already seeing a growing movement of people starting to have, well, intimate relationships with text chatbots.
One unlikely group that might become heavy users is the senior community. In fact, there are currently clinical therapeutic programs bringing Virtual Reality experiences to elders, with researchers finding that the tools can improve both loneliness and symptoms of dementia.
Though visiting a virtual version of a national park is quite different than recreating an environment taken directly from one’s past, with a seemingly life-like avatar of a now-deceased loved one.
We’re already seeing posthumous audio synthetics through a service called Hereafter. And you may be wondering how we would recreate someone’s own environment.
That will be made possible with yet even more eye-opening AI tools like NVIDIA Instant NERF, which allows you to create immersive 3D scenes, from literally just a few photographs – it really is amazing tech:
Imagine going through photobooks of a couple’s history, to create a virtual replication of the home where they raised their children or a vacation they took to the Poconos.
One could easily see someone, especially towards the end of their life, preferring to spend more time in this digital second life than they do in the real world. Should this be hindered? Does it make a difference if they have a terminal illness? What about people suffering from dementia?
As is often the case, we may only develop rules around interactive synthetic content as a reaction to the real-world cultural effects – which with tech this seductive, could be quite damaging.
The Long-Term Impacts of Synthetic Video
While interactive VR content may not become the norm for a while, some of these synthetic tools will start becoming available in 2023.
Over the coming years, we’ll see individuals and small teams create incredible content that rivals the work of the largest companies. And I imagine both legacy and new media companies with the ability to train their own models will become prodigiously productive content farms (you were just 20 years too late, Expert Village).
For viewers, this will usher in a new perpetually ever more golden era of content. It will allow for not just unprecedented choice, but a surgical precision in getting served the kinds of content that they are likely to deeply engage with.
One would hope that all these tools would give rise to a more robust creative economy. But this tidal wave of new content and creators will all be competing for the same attention — and there are only so many hours in a day to accrue watch time.
The number of views and engagement that currently lead to somewhat sustainable ad revenue may drop across the board (not to mention an entire shake-up of the branded content space). And so it wouldn’t be surprising to see industry-wide contractions across content teams, Youtube creators, and human influencers.
Where does this leave the performers that remain? On one hand, talent will now have infinite longevity, and they (or their estates) can decide to continue to act in their prime for eternity. Younger performers may never even age — or in the span of a month become old and then reverse back to their youth in their content purely based on audience trends.

And while current viewers may want to continue to see their favorite human stars out of nostalgia, at what point in the future do audiences just stop caring about Timothee Chalamet in favor of native synthetics?
The connective nature of content
I remember coming to school as a kid the day after a new Simpson’s episode, and my entire friend group would be able to quote it. Things are different now. Though there are still blockbuster movies that capture the news cycle, shows that everyone is binging at the same time, and clips that make the rounds across all the platforms.
But soon, there might just be too much content for a singular project to be able to break through to the masses, finally eroding the remaining semblance of what was once mainstream media.
And that is even before we get to the rise of personally generated media, as eventually, the technology will get so good, we’ll be able to just ask our media device to create an entire film on the fly.
You’ve just generated the most epic film and feel compelled to share it with friends – but who will have the time to watch it when every professional, amateur, and individual can be doing the same exact thing at any given moment?
Though I imagine there will still be groups of fans brought even more closely together by the ability to dive way deeper into the worlds that they love – with now not just endless storylines within say the Stars Wars Universe, but also the ability for immersive, interactive experiences.
And within these worlds, we definitely won’t always be interacting with real people. It seems inevitable that at some point in the near future, we as a society will be asking questions along the lines of — if you can develop friendships and have meaningful experiences with a synthetic avatar, does it even matter if they’re real or not?
Truthiness
When it comes to deepfakes, we may not get a perfect system, but there will definitely be something in place – tech companies have too much to lose to allow for the synthetic video landscape to become the Wild West. And I imagine governing bodies like the EU may have stricter regulations, further complicating the issue.
Overall, it feels like we have to assume that we’re moving into an era, where we can’t believe that anything we’re watching is real. This isn’t fundamentally bad, we’ll just have to accept that while something may not be real, it doesn’t mean it’s not true … though oftentimes, it’ll probably also not be true.
Thanks for reading. What felt right and what missed the mark? Let me know in the comments or feel free to email me.

